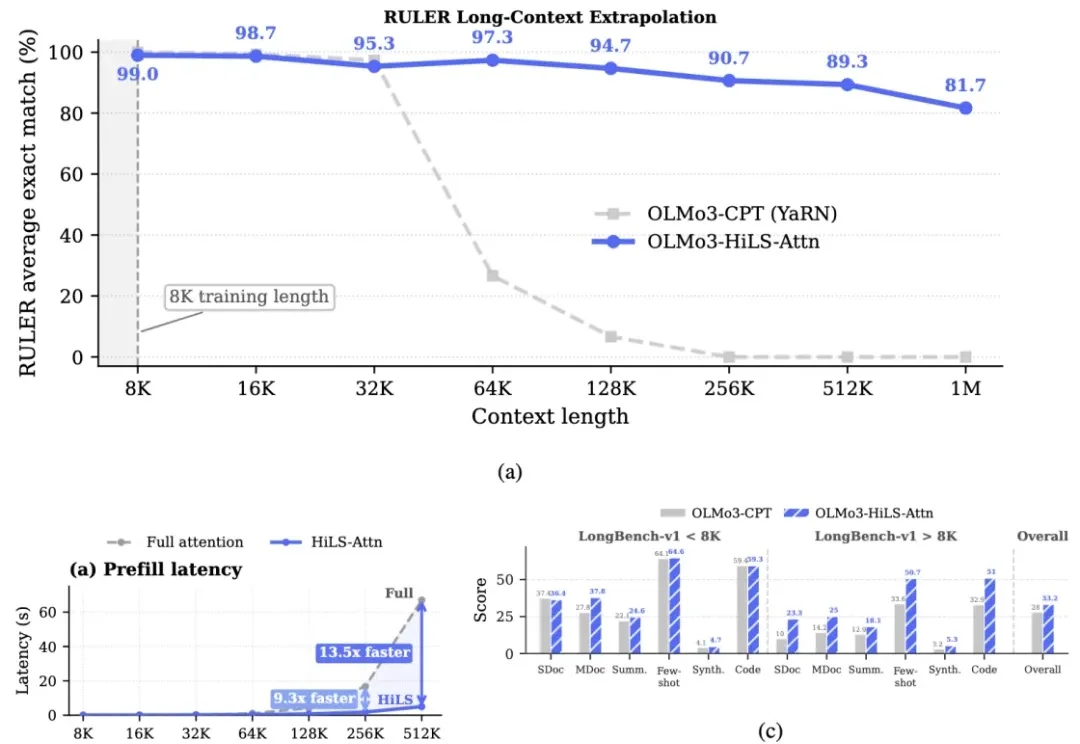
在数学上把稀疏注意力做对!腾讯Hy开源HiLS-Attention: 计算更少效果更好, 外推512倍
在数学上把稀疏注意力做对!腾讯Hy开源HiLS-Attention: 计算更少效果更好, 外推512倍让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。
来自主题: AI技术研报
8694 点击 2026-07-20 15:19
 搜索
搜索
让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。

推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
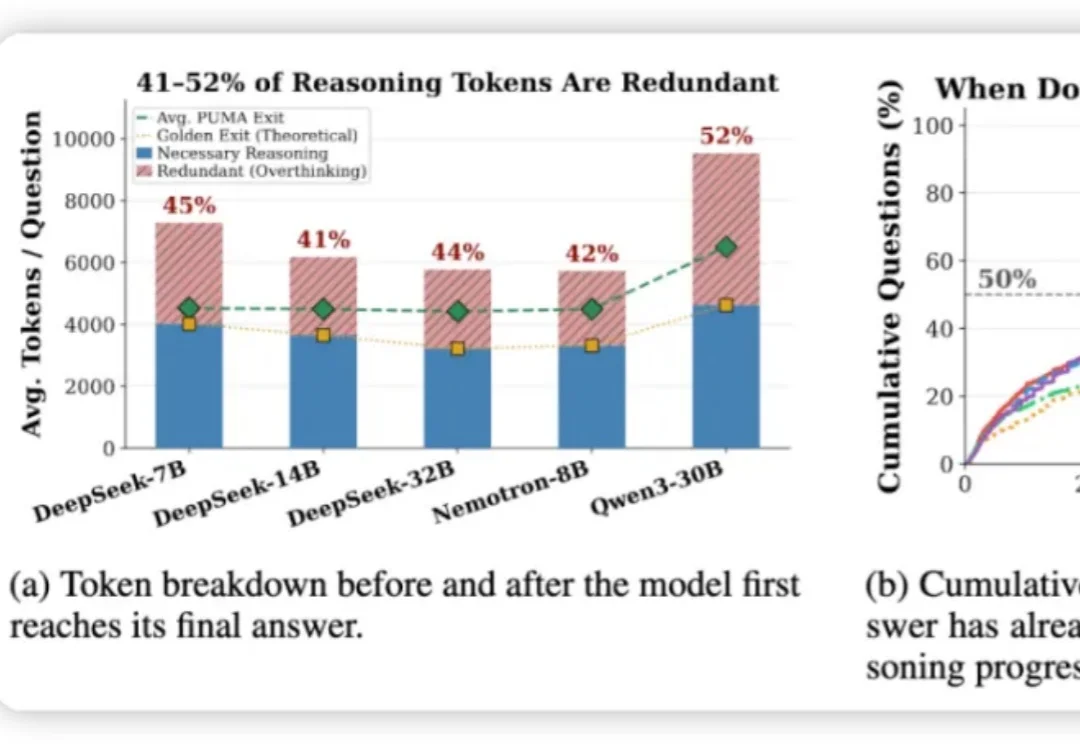
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。

机器之心编辑部 由 OpenAI 前首席技术官 Mira Murati 创立的 AI 初创公司 Thinking Machines Lab,刚刚发布了自研 AI 模型 Inkling。与 OpenAI、Anthropic 或 Google 的旗舰模型不同,Inkling 是一款开放权重模型,外部开发者和企业可以直接下载,并根据自身需求进行修改。
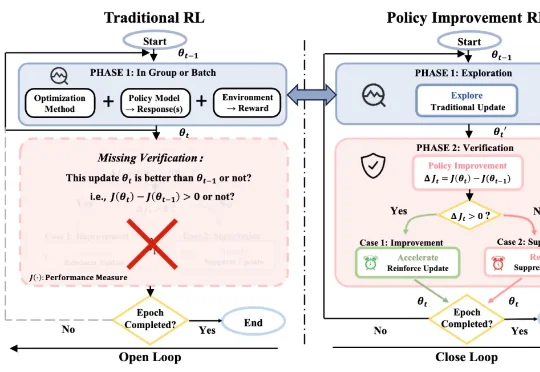
来自北航、北大、美团的研究团队提出了Policy Improvement Reinforcement Learning, PIRL,以及对应的落地算法 PIPO。这项工作关注的是大模型 RL 后训练中一个非常基础、但长期被默认跳过的问题:一次更新在当前数据上看起来优化了学习信号,是否就真的说明模型策略变强了?

月之暗面旗下新一代大模型 Kimi K3 已由员工在 X 上确认,将于本月内发布。据多方信源,K3 的参数规模将达到 2.5 万亿——这一数字不仅超越了 DeepSeek V4 Pro 的 1.6 万亿,也成为当前已公开参数规模最大的国产模型。

2026 年,风向掉头了。几个最受关注的年轻 AI 人才,开始走进大厂。罗福莉,四川宜宾乡村出身,北大硕士,DeepSeek-V2 作者之一。被雷军点名后,“天才少女”四个字在热搜上挂了很久。她去了小米,负责大模型 MiMo。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。
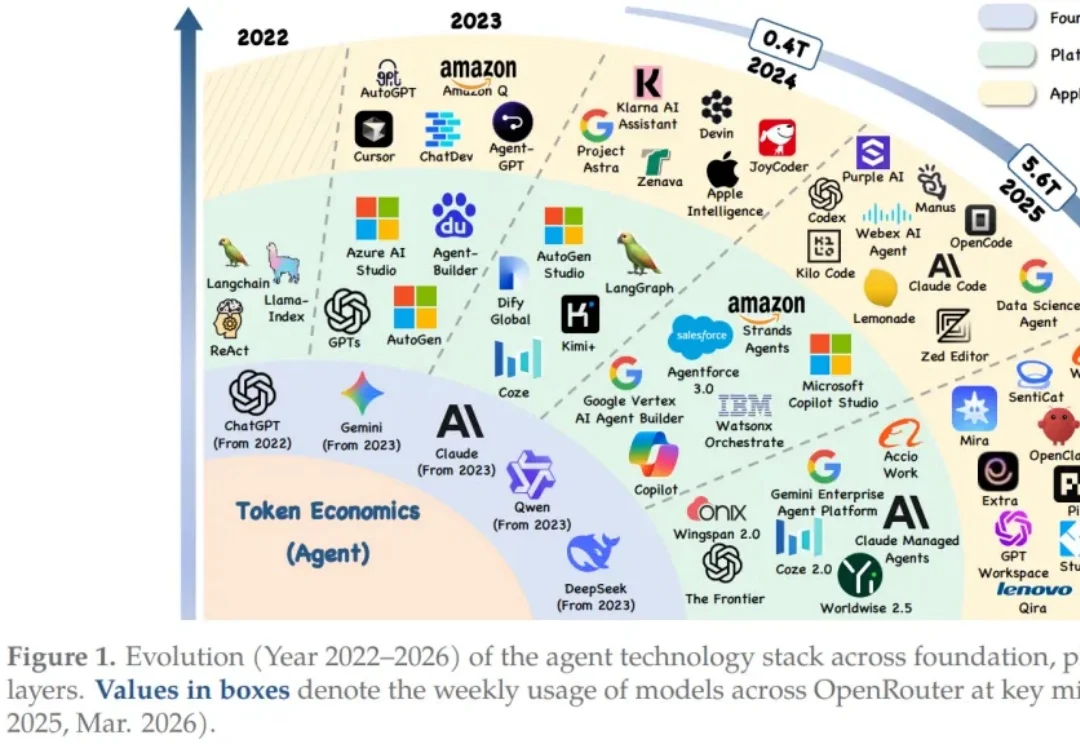
当大模型 Agent 从实验室加速走向金融、医疗、代码开发等高价值场景,一个隐秘却致命的瓶颈正在浮现:Token 的指数级消耗正引发算力、协作与安全的系统性危机。传统 “堆算力、加参数” 的线性优化已触及天花板,我们该如何在 “输出质量” 与 “经济成本” 之间找到可持续的最优解?

过去的大模型 scaling law 通常回答的是:当模型参数量、数据量和训练计算量增加后,loss 会如何下降。